
What are Canonical Tags?
A canonical tag is a HTML snippet code that tells the search engines which web page is the master version or the true original version of a group of duplicate pages.
Canonical tags are ‘hints’ rather than ‘directives’ meaning that the search engines won’t always necessarily respect each canonical tag that you specify. However, in some cases search engines may specify their own canonical tags.
What Are The Benefits of Using Canonical Tags?
The main benefit of using canonical tags is the ability to group clusters of identical or near duplicate pages together. So that, the search engines will select only one version of a page, most often the canonical URL, in the search engine listings.
Canonical tags are great to prevent the search engines listing duplicate versions of the page and avoiding near duplicate pages competing against each other in the Google rankings.
As well as removing pages from the search engine’s index, canonical tags will also consolidate the authority of canonicalised pages (duplicate versions of a page) into a canonical page (the master version or original version of the page).
For example, if page B is canonicalised to page A, any authority from external links pointing at page B will be passed across to page A.
Canonical tags are particularly useful for ecommerce sites with lots of very similar pages.
For example, the ‘red dresses’ category page will likely be very similar to the ‘dresses’ category page.
In this scenario, the ‘red dresses’ page can be canonicalised to the main ‘dresses’ page – users will still be able to navigate to the ‘red dresses’ page once on the site, but the ‘red dresses’ page won’t compete with the ‘dresses’ page in search results (plus the ‘dresses’ page inherits authority associated with the ‘red dresses’ page); giving the ‘dresses’ page the best possible chance of achieving its full visibility potential (i.e. ranking as well as it possibly can).
Where Canonical Tags Should Be Used
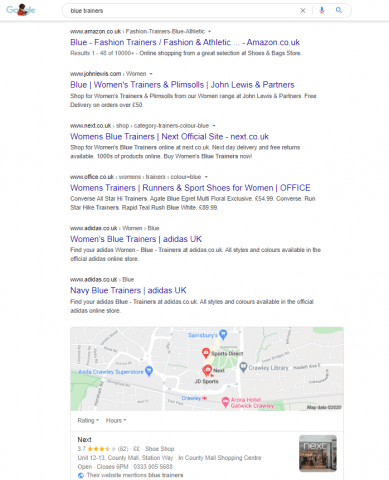
- To group very similar pages if facet URLs like colour, size, material etc are used, as with the example above (there are some situations where allowing these facets to be indexed is beneficial, for example if search engines elect to show facet-specific pages for long tail searches – see the example below where there are several blue trainer specific pages ranking for ‘blue trainers’)

- Ideally, each page should have a self referring canonical tag (unless it’s canonicalised to a different page). This could reduce the chances of Google picking a different canonical page
- Sites that use URL parameters or UTM tags that create many different versions of a page on different URLs without significantly changing the content would do well to use canonical tags to consolidate all of these URLs to one canonical version
Where Canonical Tags Shouldn’t be Used
While canonical tags are beneficial for sites that NEED to have several near-identical versions of a page (such as the examples above), there’s no point in having lots of canonicalised pages that don’t need to exist.
Of course, having identical or near-identical pages canonicalised is better than them allowing them to be indexed, but those pages not existing at all is even more optimal.
Think about it like this – if you have 1,000 canonical pages on your site, and each one of those has a canonicalised page pointing at, suddenly you have a 2,000 page site. Search engines only need to crawl 1,000 of those pages, so why allow them to crawl double the amount?
This may not be an issue on a site this size, but when if we’re talking about sites with tens of thousands or hundreds of thousands of pages – this will become an issue.
How to Check Canonical Tags
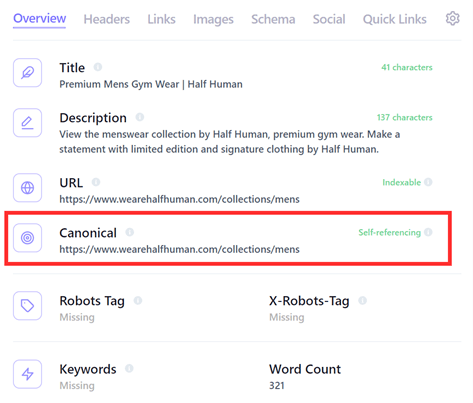
There are many tools and methods out there to check canonical tags. Arguably the quickest way to check canonical tags on-the-fly for an individual page is with a browser plugin such as ‘Detailed’ for Google Chrome. This provides a lot of important on-page information including if a page has a canonical tag, where it points to, and if it’s self-referencing or canonicalised
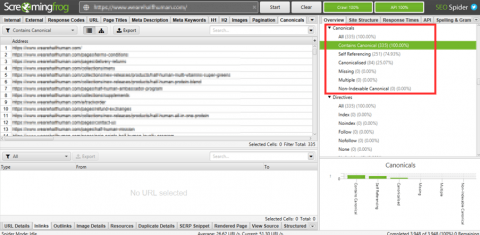
Alternatively, website crawlers are a good way to check canonical tags on scale. Screaming Frog will provide more insight into canonicalised pages, which of those are canonicalised, and which of those are self-referencing.
When A 301 Redirect Rather Than a Canonical Tag Makes Sense
If you decide that you are going to get rid of canonicalised pages that don’t need to exist, it’s best to apply a 301 redirect to the canonical page. This means that any traffic or authority associated with the redirected URL will be passed through to the final destination URL.
Once redirected, any links to the redirected pages can be deleted to stop search engines crawling them.
Setting up a 301 Redirect Using Windows Server
If you host your website on a Windows server, you will need to have administrative access to the hosting server and will need to set up the 301 redirect through IIS.
Go to “All Programs>Administrative Tools>Internet Information Services”
Navigate to the domain and right click on it, then select “Properties”
Click on the “Home Directory” tab
Select the radial button “A redirection to a URL”
Then enter the URL you want to redirect to (e.g. https://www.example.com)
Click “OK”
This will redirect the domain.
Warning: Some Advice on 301 Redirects
Ensure that the domain names are correct when implementing a permanent 301 redirect, and then double-check them again. Once implemented, test that the redirect is working properly, and make sure that you refresh the page several times to ensure you are not viewing a cached page. The reason this is vital is that using IIS incorrectly could result in your website being brought down.
Canonical Tag Summary
Canonical tags are incredibly useful for solving a number of different SEO issues – just ensure that they’re being used in the right way, and for the right reasons. Not every website needs to use canonical tags.
Audit existing canonical tags on a regular basis to make sure they are having the desired effect, and that the pages actually need to exist in the first instance. Also, make sure that you regularly check any cannibalisation issues on your site that could be solved with canonical tags.





Leave a Reply